Keywords: Model evaluation(training/cross validation/test sets), bias and variance, error analysis, skewed datasets(bias and recall)
3.1 Advice for Applying Machine Learning
3.2 Deciding what to try next


- how to do it? Let’s learn at the next video.
3.1.2 Evaluating a Model

- 주택 크기(x)로 가격을 예측하는 4차 다항식 모델이 훈련 데이터에는 잘 맞지만, 새로운 데이터에는 일반화되지 않을 수 있다.
- 여러 특징이 있는 경우 시각적 평가가 어려워지므로, 모델 성능을 평가하기 위해 더 체계적인 방법이 필요하다.
[For Regression Problem]



[For Classification Problem]

- 분류 문제에서 학습 알고리즘의 성능을 평가할 때, 테스트 오류와 훈련 오류를 측정하는 또 다른 방법이 있다.
- 로지스틱 손실 대신 알고리즘이 잘못 분류한 테스트 세트와 훈련 세트의 비율을 사용하는 것이다.

3.1.3 Model selection and training/ cross validation/ test sets


- 모델 선택을 위해 테스트 세트를 사용하는 방법을 설명하면 다음과 같다. 주택 가격 예측과 같은 회귀 문제에서 다양한 차수의 다항식을 사용해 모델을 피팅하고, 각 모델의 테스트 오류(J_test)를 계산하여 비교할 수 있다.
- 예를 들어, 1차부터 10차 다항식까지 시도하고, 가장 낮은 J_test 값을 가진 모델을 선택하는 것이다. 그
- 러나 이 절차는 테스트 세트를 모델 선택에 사용하기 때문에 실제 일반화 오류를 과소평가할 가능성이 있다. 따라서 모델 선택을 자동화하려면 훈련 및 테스트 절차를 수정해야 한다.

- 모델 선택을 자동화하려면 데이터를 훈련 세트, 교차 검증 세트, 테스트 세트로 나누어야 한다.
- 예를 들어, 데이터의 **60%**를 훈련 세트로, **20%**를 교차 검증 세트로, 나머지 **20%**를 테스트 세트로 사용한다.
- 이렇게 나누면 교차 검증 세트를 통해 다양한 모델을 평가하고 최적의 모델을 선택할 수 있다.


- 모델 선택을 위해 데이터를 훈련 세트, 교차 검증 세트, 테스트 세트로 나눈다. 훈련 세트로 모델을 학습하고, 교차 검증 세트로 교차 검증 오류(J_cv)를 계산해 모델을 평가한다.
- 가장 낮은 J_cv를 가진 모델을 선택한 후, 테스트 세트로 최종 일반화 오류(J_test)를 보고한다.
- 이 방법은 테스트 세트를 모델 선택에 사용하지 않기 때문에 일반화 오류를 더 공정하게 평가할 수 있다.

3.2 Bias and variance
3.2.1 Diagnosing bias and variance


3.2.2 Regularization and bias/variance

- how can you choose a good value of Lambda?


- 교차 검증을 통해 다양한 값을 평가하면 적절한 t(degree of polynomial) 값이나 Lambda 값을 선택하는 데 도움이 된다.
- **높은 훈련 세트 오류(J_train)**는 높은 bias를 나타내며, 교차 검증 오류(J_cv)가 J_train보다 훨씬 높을 경우 이는 높은 variance를 의미한다.
- 그러나 여기서 high 와 very high를 어떻게 구분할 수 있을까?
- 이 의미를 명확히 하기 위해서는 기준 성능 수준을 설정할 필요가 있다. 이는 J_train과 J_cv의 값이 높은지 낮은지 판단하는데 도움을 준다. 다음 장에서 살펴보자.
3.2.3 Establishing a baseline level of performance

- 다음은 J-train과 JCV를 분석하여 알고리즘의 bias와 variance 문제를 판단하는 예이다.
- 음성 인식 시스템의 훈련 오류가 10.8%이고 교차 검증 오류가 14.8%라고 가정하자.
- 처음에는 훈련 오류가 높아 높은 bias 문제로 생각될 수 있다.
- 그러나 인간의 오류율이 10.6%인 상황에서, 훈련 오류가 10.8%인 것은 사실 잘 작동하는 것이다.
- 반면, 교차 검증 오류와 훈련 오류 사이의 차이가 4%로 크기 때문에, 이 알고리즘은 bias 문제보다는 variance 문제가 더 크다고 판단할 수 있다.

- 훈련 오류를 판단할 때는 기준 성능 수준을 설정하는 것이 유용하다.
- 이를 설정하는 일반적인 방법은 인간의 성능을 측정하는 것이다. 인간은 음성, 이미지, 텍스트와 같은 비정형 데이터를 이해하는 데 뛰어나기 때문이다.
- 또 다른 방법은 기존 알고리즘이나 경쟁 알고리즘의 성능을 측정하거나**, 이전 경험을 바탕**으로 추정하는 것이다.
- 기준 성능 수준은 알고리즘이 도달해야 하는 목표 오류 수준을 설정하는 데 도움이 된다.

모델의 bias와 variance를 평가하기 위해 두 가지 주요 값을 측정한다:
- 훈련 오류와 기준 성능(예: 인간 수준 성능) 간의 차이: 큰 차이는 높은 bias를 의미한다.
- 훈련 오류와 교차 검증 오류 간의 차이: 큰 차이는 높은 variance를 의미한다.
이 방법을 통해 모델의 성능을 더 정확하게 평가할 수 있으며, 높은 bias와 높은 variance 문제를 동시에 발견할 수도 있다.
3.2.4 Learning Curves

- 학습 곡선을 통해 모델이 더 많은 훈련 예제(m_train)를 학습함에 따라 훈련 오류(J_train)는 증가하고 교차 검증 오류(J_cv)는 감소하는 경향을 파악할 수 있다.

- 모델이 고편향(underfitting/ high bias)인 경우, 훈련 오류(J_train)와 교차 검증 오류(J_cv)는 일정 수준에서 평탄해지며, 더 많은 훈련 데이터를 추가해도 오류가 크게 줄어들지 않는다.

- 고분산(high variance) 시나리오에서 학습 곡선은 다음과 같다: 훈련 오류(J_train)는 훈련 세트 크기 증가에 따라 증가하고, 교차 검증 오류(J_cv)는 훈련 오류보다 훨씬 높게 나타난다.
- 이 경우 더 많은 훈련 데이터를 추가하면 교차 검증 오류가 감소할 수 있어 성능 향상이 가능하다.
- 고분산 문제는 훈련 세트에서 잘 작동하지만 새로운 데이터에는 잘 일반화되지 않기 때문에, 더 많은 데이터를 추가하는 것이 도움이 된다.
- 추천방법: Learning curve모양 상상해보기그러나 이렇게 학습 곡선을 그리는 것은 많은 크기의 훈련 세트를 사용하여 여러 모델을 훈련시키는 것이기 때문에 계산 비용이 많이 들 수 있다. 따라서 실제로는 자주 사용되지 않지만, 학습 곡선을 시각적으로 상상하는 것은 알고리즘의 성능을 이해하고 고편향 또는 고분산 문제를 파악하는 데 도움이 될 수 있다.
- 머신러닝 응용 프로그램을 구축할 때 학습 곡선을 그려볼 수 있다. 예를 들어, 1,000개의 훈련 예제가 있는 경우, 100개의 예제로만 모델을 훈련시키고 훈련 오류와 교차 검증 오류를 확인한 후, 200개의 예제로 모델을 훈련시키고 나머지 800개의 예제를 보류하는 식으로 반복하면서 J_train과 J_cv를 플롯할 수 있다. 이를 통해 학습 곡선이 고편향(high bias)인지 고분산인지 확인할 수 있다.
3.2.5 Deciding what to do next: revisited

💡편향(bias)과 분산(variance)은 쉽게 배울 수 있지만, 완전히 이해하고 마스터하는 데는 오랜 시간이 걸리는 개념이다. 실제로 많은 경험을 통해 반복적으로 연습해야 한다. 이 개념들을 잘 이해하면 학습 알고리즘을 개발할 때 무엇을 시도할지 결정하는 데 큰 도움이 된다.
3.2.6 Bias/variance and neural networks

- 편향(bias)과 분산(variance)이 모두 알고리즘의 성능을 저해한다.
- 전통적으로는 모델의 복잡도와 정규화 매개변수를 조절해 편향과 분산 사이의 균형을 맞추려 했다.
- 하지만, 신경망과 대용량 데이터의 등장으로 이러한 편향-분산 트레이드오프 문제를 해결할 새로운 방법을 제공하게 되었다.

- 신경망과 대용량 데이터는 편향(bias)과 분산(variance) 문제를 동시에 해결할 수 있는 새로운 방법을 제공한다.
- 큰 신경망은 일반적으로 낮은 편향을 가지며, 충분히 큰 신경망을 사용하면 훈련 세트에 대해 잘 맞출 수 있다.
- 이로 인해 편향이 높다면 더 큰 신경망을 사용하고, 분산이 높다면 더 많은 데이터를 확보하여 문제를 해결할 수 있다.
- 단, 신경망이 너무 커지면 계산 비용이 증가하고, 데이터 확보에 한계가 있을 수 있다.
- 이 방법은 고성능 컴퓨터와 GPU 덕분에 가능하며, 데이터가 충분히 많은 경우 효과적이다.
- 편향과 분산 문제는 알고리즘 개발 중에도 변화할 수 있어, 상황에 맞게 조정이 필요하다.

- 큰 신경망은 잘 선택된 정규화를 사용하면 작은 신경망보다 성능이 더 좋거나 최소한 비슷하다.
- 큰 신경망의 과적합 위험은 정규화를 통해 완화할 수 있다.
- 그러나 큰 신경망은 계산 비용이 더 많이 들기 때문에 훈련 및 추론 과정이 느려질 수 있다.

- 신경망 정규화를 위해서는 손실 함수에 정규화 항을 추가하면 되며, 이는 모든 가중치에 대해 λ/2m * Σw² 형태로 나타난다.
- 텐서플로우에서는 모델 레이어에 kernel_regularizer를 추가하여 쉽게 정규화를 구현할 수 있다.
To summarize,
- It hardly ever hurts to have a larger neural network so long as you regularize appropriately.
- one caveat being that having a larger neural network can slow down your algorithm.
- So maybe that's the one way it hurts, but it shouldn't hurt your algorithm's performance for the most part and in fact it could even help it significantly.
- So long as your training set isn't too large, a neural network, especially large neural network is often a low bias machine.
- It just fits very complicated functions very well, which is why when I'm training neural networks, I find that I'm often fighting variance problems rather than bias problems, at least if the neural network is large enough.
- So the rise of deep learning has really changed the way that machine learning practitioners think about bias and variance.
- Having said that even when you're training a neural network measuring bias and variance and using that to guide what you do next is often a very helpful thing to do.
3.3 Machine Learning Development Process
3.3.1 Iterative loop of ML development

머신러닝 시스템 개발 과정에서는 반복적인 개발 루프를 통해 최적의 성능을 달성하게 된다. 먼저, 시스템의 전체 아키텍처를 결정하고 모델을 선택하며 데이터를 선택하고 하이퍼파라미터를 설정한다. 그런 다음 모델을 구현하고 훈련한다. 초기 훈련 성능이 기대에 미치지 못할 경우, 바이어스 및 분산 분석과 오류 분석을 통해 진단을 수행한다. 이 진단 결과를 바탕으로 신경망 크기 조정, 정규화 파라미터 변경, 데이터 추가, 특징 변경 등의 결정을 내린다. 이 과정을 여러 번 반복하여 원하는 성능을 달성하게 된다.


3.3.2 Error analysis
In terms of the most important ways to help you run diagnostics to choose what to try next to improve your learning algorithm performance, I would say bias and variance is probably the most important idea and error analysis would probably be second on my list.

- 오류 분석은 교차 검증 세트에서 잘못 분류된 예제를 수동으로 검토하여 알고리즘이 어디서 잘못되는지 통찰을 얻는 과정이다.
- 예를 들어, 500개의 교차 검증 예제 중 100개를 잘못 분류했다면, 이 100개의 예제를 검토하여 공통된 주제나 특성을 찾고, 각 유형의 오류 빈도를 기록한다. (만약 잘못분류가 5000개중 1000개라서 모두 살펴보는 시간이 부족하다면 랜덤하게 100개의 subsample을 살펴보면 된다.)
- 이를 통해 주요 문제 영역을 파악하고 우선순위를 정하는 데 도움을 받을 수 있다.
- 분석 결과에 따라 특정 유형의 데이터 수집, 새로운 특징 생성 등을 통해 알고리즘 성능을 개선할 수 있는 아이디어를 얻는다.
3.3.3 Adding data


- 데이터 증강은 특히 이미지와 오디오 데이터에서 널리 사용되는 기법으로, 기존 훈련 예제를 변형하여 새로운 훈련 예제를 생성한다.
- 예를 들어, OCR 문제에서 'A' 문자의 이미지를 회전시키거나, 크기를 조절하거나, 대조를 변경하여 변형해도 여전히 'A'로 인식하도록 학습한다.
- 이 기법을 통해 훈련 데이터 세트를 확장하여 알고리즘의 성능을 향상시킬 수 있다.
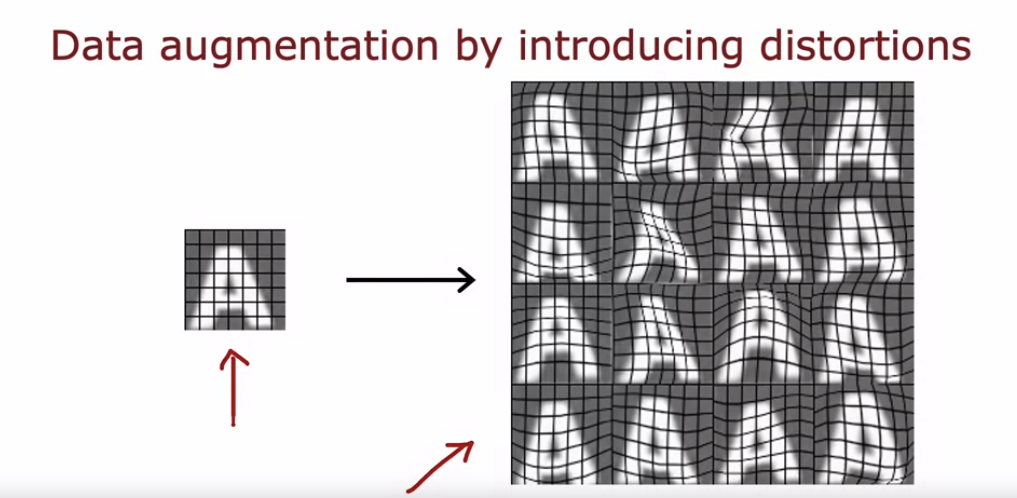
- 데이터 증강의 더 고급 예로, 'A' 문자에 그리드를 적용하고 무작위 왜곡을 통해 다양한 변형된 'A' 문자를 생성할 수 있다.
- 이러한 왜곡 과정을 통해 단일 이미지에서 여러 훈련 예제를 만들어 학습 알고리즘이 'A' 문자를 더 견고하게 인식할 수 있도록 한다.

- 음성 인식에서도 데이터 증강 기법을 사용할 수 있다.
- 예를 들어, 원본 오디오 클립에 군중 소음, 자동차 소음, 또는 나쁜 전화 연결 소음을 추가하여 다양한 환경에서의 오디오 클립을 생성할 수 있다.
- 이러한 변형된 오디오 클립을 학습 데이터로 사용하면 음성 인식 시스템의 성능을 향상시킬 수 있다.
- 데이터 증강 시 적용하는 변형이나 왜곡은 테스트 세트에서 나타날 수 있는 노이즈나 왜곡을 대표해야 한다.

- 예를 들어, 글자 'A'를 왜곡하거나 오디오에 배경 소음을 추가하는 것은 테스트 세트에서 기대되는 변형을 반영하기 때문에 유용하다.
- 반면에 무작위로 의미 없는 노이즈를 추가하는 것은 도움이 되지 않는다.
- 데이터 증강의 핵심은 변형된 데이터가 테스트 세트와 유사한 특성을 가지도록 하는 것이다.



- 데이터 합성은 기존 데이터를 변형하는 대신 완전히 새로운 예제를 생성하는 기법이다.
- 예를 들어, Photo OCR(사진 문자 인식)에서는 다양한 폰트를 사용하여 인위적으로 텍스트 이미지를 생성할 수 있다.
- 이렇게 생성된 합성 데이터는 실제 데이터와 매우 유사하게 보이며, 많은 양의 학습 데이터를 만들어 알고리즘의 성능을 크게 향상시킬 수 있다. 이 기법은 주로 컴퓨터 비전 작업에 많이 사용된다.

3.3.4 Transfer Learning: using data from a different task

- 전이 학습은 적은 데이터로도 성능을 높일 수 있는 기법이다.
- 예를 들어, 손글씨 숫자 인식 문제에서 데이터가 부족할 때, 고양이, 개, 자동차 등 1000가지 클래스의 백만 개 이미지로 사전 학습된 신경망을 활용할 수 있다.
- 이 신경망의 마지막 층을 손글씨 숫자 인식용으로 바꾸고, 이전 층의 매개변수는 고정하거나 초기값으로 사용해 미세 조정을 통해 모델을 학습한다.
- 작은 데이터셋일 경우 출력층만 학습하는 것이 좋고, 더 큰 데이터셋이면 모든 매개변수를 학습하는 것이 효과적이다.
- 많은 연구자들이 사전 학습된 모델을 온라인에 공개하고 있어, 이를 다운로드하여 전이 학습을 통해 빠르게 성능을 높일 수 있다.

- 전이 학습은 신경망의 초기 층이 에지, 모서리, 기본 모양 등을 인식하는 일반적인 특징을 학습하기 때문에, 고양이, 개, 자동차 등을 인식하는 신경망을 손글씨 숫자 인식에 활용할 수 있다.
- 다만, 사전 학습과 미세 조정 단계의 데이터 유형이 동일해야 한다.
- 예를 들어, 이미지 인식을 위해 학습된 신경망은 이미지 데이터에만, 오디오 인식을 위해 학습된 신경망은 오디오 데이터에만 적용 가능하다.
- e.g. GPT-3, or BERTs, or ImageNet

3.3.5 Full cycle of a machine learning project

머신러닝 프로젝트의 전체 주기는 다음과 같다:
- 프로젝트 범위 설정: 작업할 프로젝트 결정 (예: 음성 인식을 통한 음성 검색).
- 데이터 수집: 학습에 필요한 데이터 수집 및 레이블링.
- 모델 학습 및 개선: 모델을 학습하고 오류 분석 및 바이어스-분산 분석을 통해 성능을 향상시킴.
- 모델 배포 및 유지 관리: 모델을 실제 환경에 배포하고 성능을 지속적으로 모니터링 및 유지 관리.
이 과정을 통해 프로젝트를 반복적으로 개선하고 최종적으로 실사용 가능한 모델을 개발한다.

- 고성능 머신러닝 모델(예: 음성 인식 모델)을 배포하는 일반적인 방법은 모델을 서버(추론 서버)에 구현하는 것이다.
- 모바일 앱이 사용자 입력(음성 클립)을 서버에 보내면, 서버는 모델을 통해 예측(텍스트 변환)을 반환한다. 이는 API 호출을 통해 이루어진다.
- 응용 프로그램의 규모에 따라 필요한 소프트웨어 엔지니어링의 양이 다르다.
- 대규모 사용자 지원 시 서버 확장성 관리가 중요하며, 입력 데이터와 예측 데이터를 기록하여 시스템 모니터링 및 성능 저하 시 모델 재훈련 및 업데이트를 수행해야 한다.
- 이를 체계적으로 관리하는 분야가 **MLOps(Machine Learning Operations)**이다. MLOps는 모델의 안정성, 확장성, 효율성을 보장하고, 필요 시 모델 업데이트를 가능하게 한다.
3.3.6 Fairness, bias, and ethics


How to be more fair, less biased, and more ethical

여기서는 체크리스트가 아닌, 더 공정하고 편향되지 않으며 윤리적인 작업을 위한 일반적인 지침을 제공하고자 한다. 시스템 배포 전 다음과 같은 단계를 통해 작업을 더 공정하고 윤리적으로 만들 수 있다:
- 다양한 팀 구성: 다양한 배경(성별, 인종, 문화 등)의 팀을 구성하여 가능한 문제를 브레인스토밍한다. 이는 문제를 인식하고 해결할 가능성을 높인다.
- 문헌 검색: 해당 산업이나 응용 분야의 기준이나 지침을 조사한다. 예를 들어, 금융 산업에서는 대출 승인 시스템의 공정성과 편향성에 대한 기준이 마련되고 있다.
- 시스템 감사: 모델을 배포하기 전에 특정 성별이나 인종 등의 하위 그룹에 대해 편향이 있는지 성능을 측정하고 문제를 해결한다.
- 완화 계획 수립: 문제 발생 시 즉시 대처할 수 있는 완화 계획을 마련하고, 배포 후에도 지속적으로 모니터링하여 문제를 신속히 해결한다. 예를 들어, 자율주행차 팀은 사고 발생 시 대응 계획을 미리 마련한다.
윤리, 공정성, 편향성 문제는 가볍게 여길 것이 아니며, 이는 머신러닝 시스템의 성공적인 배포와 운영에 매우 중요하다. 모든 머신러닝 실무자가 이러한 문제를 인식하고, 개선하는 노력을 기울여야 한다.
3.4 Skewed datasets (Optional)
3.4.1 Error metrics for skewed datasets

- 데이터의 양성 및 음성 예제 비율이 크게 왜곡된 경우, 일반적인 오류 메트릭인 정확도는 적절하지 않다.
- 예를 들어, 희귀 질병을 진단하는 이진 분류기를 훈련시키는 경우, 질병이 있는 경우 y=1, 없는 경우 y=0이라고 할 때, 테스트 세트에서 1%의 오류를 달성했다고 가정해보자.
- 이는 99%의 정확도를 의미하며 좋은 결과처럼 보일 수 있다. 그러나 질병이 희귀한 경우, 단순히 y=0을 출력하는 프로그램만으로도 99.5%의 정확도를 달성할 수 있다.
- 이는 매우 단순한 알고리즘이지만, 실제로는 유용하지 않다. 따라서 오류율이 1%인 알고리즘이 실제로 좋은 결과인지 나쁜 결과인지 판단하기 어렵다.
- 왜곡된 데이터 세트에서는 단순한 분류 오류 대신 다른 오류 메트릭을 사용하여 학습 알고리즘의 성능을 평가해야 한다.
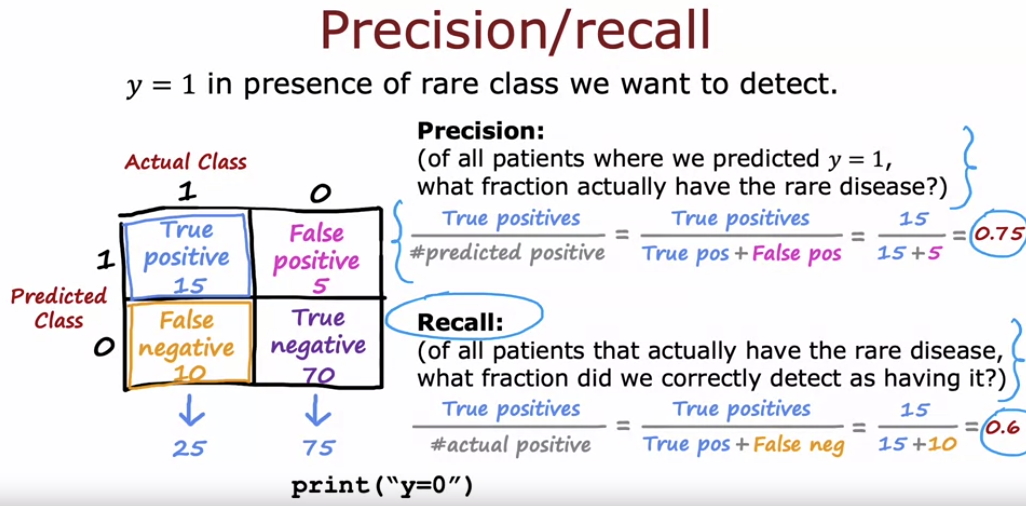
- 편향된 데이터 셋을 다룰 때는 정확도 대신 정밀도와 재현율 같은 다른 오류 메트릭을 사용하는 것이 유용하다.
- 정밀도는 예측한 양성 사례 중 실제 양성의 비율을 나타내고, 재현율은 실제 양성 사례 중 올바르게 예측한 비율을 의미한다.
- 예를 들어, 희귀 질병을 진단하는 모델에서 정밀도는 75%, 재현율은 60%일 수 있다. 정밀도와 재현율을 함께 사용하면, 모델이 예측한 양성이 실제로 얼마나 정확한지, 그리고 실제 양성 사례 중 얼마나 많은 부분을 잘 찾아내는지 평가할 수 있다.
- 이는 단순히 y=0을 출력하는 비유용한 모델을 피하고, 모델의 유용성을 높이는 데 도움을 준다.
3.4.2 Trading off precision and recall

- 학습 알고리즘에서 높은 정밀도와 높은 재현율을 동시에 가지는 것이 이상적이다.
- 정밀도는 예측한 양성 사례 중 실제 양성의 비율을 나타내고, 재현율은 실제 양성 사례 중 올바르게 예측한 비율을 의미한다.
- 그러나 실제로는 정밀도와 재현율 사이에 트레이드오프가 존재한다.
- 예를 들어, 로지스틱 회귀를 사용하여 예측할 때, 기본적으로 0.5를 임계값으로 설정하여 그 이상이면 양성(1)으로 예측하고, 미만이면 음성(0)으로 예측한다.
- 그러나 더 높은 정밀도를 원한다면 이 임계값을 0.7로 올려야 하며, 이 경우 예측의 정확도가 높아져 정밀도는 증가하지만 재현율은 감소한다.
- 반대로, 재현율을 높이기 위해 임계값을 0.3으로 낮추면, 예측의 정확도가 낮아져 정밀도는 감소하지만 재현율은 증가한다.
- 따라서, 각 임계값에 따른 정밀도와 재현율을 고려하여 최적의 임계값을 선택하는 것이 중요하다.
- 이는 교차 검증으로 쉽게 할 수 없고, 각 응용 분야에 따라 직접 설정해야 하는 작업이다.

- 정밀도(precision)와 재현율(recall)을 자동으로 조정하려면 F1 스코어를 사용하는 것이 좋다.
- F1 스코어는 정밀도와 재현율을 결합하여 단일 점수로 평가할 수 있게 해주며, 낮은 값에 더 큰 비중을 둔다.
- 이는 정밀도나 재현율 중 하나가 매우 낮을 때 해당 알고리즘의 유용성이 떨어진다는 점을 반영한다.
- F1 스코어는 정밀도와 재현율의 **조화 평균(harmonic mean)**으로 계산되며, 이를 통해 가장 적절한 알고리즘을 선택할 수 있다.
- 예를 들어, 세 알고리즘의 F1 스코어를 계산하면, F1 스코어가 가장 높은 알고리즘을 선택하는 것이 바람직하다.
'AI Study' 카테고리의 다른 글
| Advanced Learning Algorithms #4 (Decision Tree Model ) (0) | 2024.07.06 |
|---|---|
| Advanced Learning Algorithms #2 (Neural Network Training) (0) | 2024.07.02 |
| Advanced Learning Algorithms #1 (Neural Networks) (0) | 2024.07.01 |
| Supervised Machine Learning Regression and Classification #2 (0) | 2024.06.29 |
| Supervised Machine Learning Regression and Classification #1 (0) | 2024.06.26 |



